



Next: Specifying The Fault-Intolerant Programs
Up: No Title
Previous: Introduction
Overview
In this chapter, we present a quick overview of our framework. We also present the architecture of the framework where we show different components and their relationships.
We first introduce the architecture of our framework (cf. Figure 2.1) that shows how it enables the addition of fault-tolerance to an existing fault-intolerant program. Then, we describe the input and the output of our framework. Further, we illustrate how the users can interact with the framework in order to semi-automatically synthesize a fault-tolerant program from its fault-intolerant version.
The framework consists of the components that represent the program being synthesized, faults, program invariant, program specification, and the synthesis algorithm. Given a fault-intolerant program and a particular class of faults, the framework generates the reachability graph of the program. Then, the synthesis algorithm iteratively manipulates the initial reachability graph in order to generate the reachability graph of the fault-tolerant program. At each step of the synthesis, the reachability graph represents an intermediate program that is being synthesized.
Figure:
The framework architecture.
![\includegraphics[ scale=0.75]{arch.eps}](img6.gif) |
The synthesis algorithm by itself consists of the following steps: identify ms, identify mt, remove mt, mark invariant, and ResolveDeadlock. The set of states ms identifies states from where safety of specification will be violated by one or more fault transitions. The set of transitions mt represents the transitions that reach ms or directly violate safety. After removing mt transitions from the reachability graph, the synthesis algorithm resolves deadlock states (if any). We refer the reader to [#!frmwrktech!#] for further information.
The input/output of the framework.
We use Dijkstra's guarded commands [#!dij76!#] as the interaction
language between the user and the synthesis framework. A guarded
command (action) is of the form
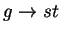 ,
where g is a state
predicate and st is a statement that updates the
program variables. The guarded command
can be
executed in a state where g is true; to execute this command, st is
executed atomically.
In other words, a guarded command includes all program transitions
,
where g is a state
predicate and st is a statement that updates the
program variables. The guarded command
can be
executed in a state where g is true; to execute this command, st is
executed atomically.
In other words, a guarded command includes all program transitions
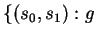 holds at s0 and the execution of st at s0 takes
the program to state
holds at s0 and the execution of st at s0 takes
the program to state 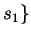 .
The faults are also modeled as a set of guarded commands that update
program variables. The invariant of the fault-intolerant program is represented as a state predicate.
Since we internally identify the safety specification by a set of transitions that the fault-tolerant program should not execute (i.e., the set of safety-violating transitions), the safety specification is specified as a set of transitions as well. We divide the specification of safety-violating transitions into three parts: destination, and relation. In the destination part, the users can specify the safety-violating transitions that are identified only by their destination states. In the relation part, the users specify the safety-violating transitions that are identified by both their source and destination states. Finally, the output is also in the guarded command language. (As an example, we present a masking fault-tolerant agreement program in the Appendix that tolerates both failstop and Byzantine faults.)
User interactions.
Although the framework can automatically synthesize a fault-tolerant program without user intervention, there are some situations where (i) user intervention can help to speed up the synthesis of fault-tolerant programs, or (ii) a fully automatic approach fails.
Hence, our framework permits developers to semi-automatically supervise the synthesis procedure. In such supervised synthesis, the fault-tolerance developers interact with the framework and apply their insights during the synthesis. In order to achieve this goal, we have devised some interaction points where the developers can stop the synthesis algorithm and query it.
At each interaction point, the users can make the following kinds of queries: (i) apply a specific heuristic for a particular task that the framework should try to satisfy and the strategies that it should use to satisfy that predicate); (ii) apply some heuristics in a particular order; (iii) view the incoming program (respectively, fault) transitions to a particular state; (iv) view the outgoing program (respectively, fault) transitions from a particular state; (v) check the membership of a particular state (respectively, transition) to a specific set of states (respectively, transition); e.g., check the membership of a given state s in the set of states ms, and finally (vi) view the intermediate representation of the program that is being synthesized.
The developers of fault-tolerance can use the queries to obtain
the current version of the program and choose the additional steps (e.g., resolving deadlock states, resolving non-progress cycles, etc.) that need to be taken for adding fault-tolerance.
While we expect that the queries included in this version will be
sufficient for a large class of programs, we also provide an
alternative for the case where these queries are
insufficient. Specifically, in this case, the users of our framework
can obtain the corresponding intermediate program in Promela modeling
language [#!promela!#]; this program can then be checked by SPIN to
determine the exact scenario where the intermediate version does not
provide the required fault-tolerance. We note that while the code that interprets the counterexamples given by SPIN is not currently implemented, it will be available in the next version of the framework.
.
The faults are also modeled as a set of guarded commands that update
program variables. The invariant of the fault-intolerant program is represented as a state predicate.
Since we internally identify the safety specification by a set of transitions that the fault-tolerant program should not execute (i.e., the set of safety-violating transitions), the safety specification is specified as a set of transitions as well. We divide the specification of safety-violating transitions into three parts: destination, and relation. In the destination part, the users can specify the safety-violating transitions that are identified only by their destination states. In the relation part, the users specify the safety-violating transitions that are identified by both their source and destination states. Finally, the output is also in the guarded command language. (As an example, we present a masking fault-tolerant agreement program in the Appendix that tolerates both failstop and Byzantine faults.)
User interactions.
Although the framework can automatically synthesize a fault-tolerant program without user intervention, there are some situations where (i) user intervention can help to speed up the synthesis of fault-tolerant programs, or (ii) a fully automatic approach fails.
Hence, our framework permits developers to semi-automatically supervise the synthesis procedure. In such supervised synthesis, the fault-tolerance developers interact with the framework and apply their insights during the synthesis. In order to achieve this goal, we have devised some interaction points where the developers can stop the synthesis algorithm and query it.
At each interaction point, the users can make the following kinds of queries: (i) apply a specific heuristic for a particular task that the framework should try to satisfy and the strategies that it should use to satisfy that predicate); (ii) apply some heuristics in a particular order; (iii) view the incoming program (respectively, fault) transitions to a particular state; (iv) view the outgoing program (respectively, fault) transitions from a particular state; (v) check the membership of a particular state (respectively, transition) to a specific set of states (respectively, transition); e.g., check the membership of a given state s in the set of states ms, and finally (vi) view the intermediate representation of the program that is being synthesized.
The developers of fault-tolerance can use the queries to obtain
the current version of the program and choose the additional steps (e.g., resolving deadlock states, resolving non-progress cycles, etc.) that need to be taken for adding fault-tolerance.
While we expect that the queries included in this version will be
sufficient for a large class of programs, we also provide an
alternative for the case where these queries are
insufficient. Specifically, in this case, the users of our framework
can obtain the corresponding intermediate program in Promela modeling
language [#!promela!#]; this program can then be checked by SPIN to
determine the exact scenario where the intermediate version does not
provide the required fault-tolerance. We note that while the code that interprets the counterexamples given by SPIN is not currently implemented, it will be available in the next version of the framework.
Next: Specifying The Fault-Intolerant Programs
Up: No Title
Previous: Introduction
Ali Ebnenasir
2003-10-26